
| Deep Learning Hardware |
Applications like self-driving car, wearable device, and Internet-of-Things (IoT) are key technologies that will lead us to upcoming true intelligent world. Future systems must employ a brain-like intelligent hardware that can efficiently process these applications, especially under the mobile environment.
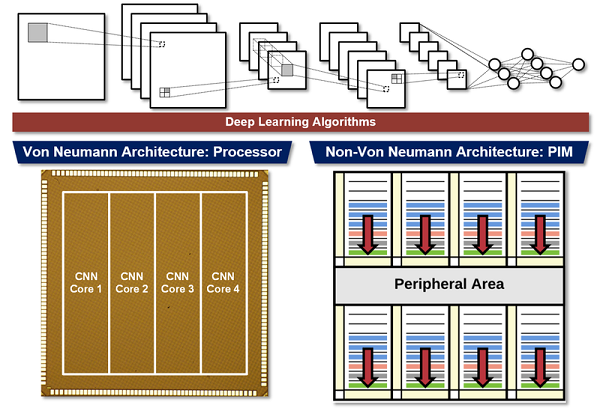
Our MVLSI Multimedia Processor group focuses on the VLSI implementation of an energy-efficient intelligent hardware based on deep learning algorithms. Deep learning algorithms such as Convolutional Neural Network and Recurrent Neural Network are our primary target for the implementation of a highly-accurate, yet energy-efficient intelligent hardware. In designing hardware for deep learning algorithms, two fundamentally different computing architectures can be considered: Von Neumann and Non-Von Neumann architecture.
In Von Neumann architecture, processor and memory are located in separated places and they are connected with buses. Since it serves as the basis for almost all modern computers, Von Neumann architecture has been the primary candidate for deep learning hardware. Our group implements processors that accelerate deep neural networks such as CNN, RNN, and SNN based on Von Neumann architecture. Also, we design an energy efficient hardware architecture and methodology for deep learning algorithms.
On the other hands, any computer architecture in which the underlying model of computation is different from Von Neumann architecture is called Non-Von Neumann architecture. Processing in-Memory (PIM) technique where computing units and memory are fused together is an example, and it is becoming a promising solution for processing large-scale deep neural networks as their large memory requirements incur a significant bottleneck in Von Neumann architecture.
